Technique
20 février 2014
Avec le déploiement de réseaux 4G/LTE et la démocratisation de terminaux compatibles, les solutions de voix sur LTE (Voice over LTE ou VoLTE) se précisent. Réseau de données par excellence, la LTE ne permet pas de passer des appels « voix », à l’exception de l’usage de la voix sur IP (VoIP). Différentes approches ont été envisagées par les opérateurs télécom.
André PEREZ, consultant et formateur LTE et IMS pour NEXCOM Systems aborde ces différentes approches (CS FallBack, SRVCC, …), ainsi que les impacts et interactions avec les infrastructures existantes (IMS) dans un article très détaillé :
Le terme LTE (Long Term Evolution) est utilisé pour désigner les réseaux de mobiles 4G. En fait, il conviendrait de nommer ces réseaux sous le vocable d’EPS (Evolved Packet Service), le terme LTE étant plutôt réservé pour dénommer l’interface radioélectrique entre le réseau 4G et le mobile.
Le service téléphonique est rempli à partir de deux fonctions de base : le transport de la voix et le traitement de la signalisation téléphonique. Le terme Voix sur LTE ou VoLTE (Voice over LTE) est le terme consacré pour désigner le transport de la voix sur IP assuré par le réseau EPS, dans le cadre de la fourniture du service téléphonique à travers une plate-forme IMS.
Lire la suite de l’article VoLTE… (PDF, 370ko)
NEXCOM Systems propose bien évidemment de nombreuses formations sur la LTE, la LTE-Advanced et l’IMS, couvrant les fondamentaux aux concepts plus poussés (interactions avec l’IMS, VoLTE, …). N’hésitez pas à nous contacter pour planifier votre future formation ou obtenir davantage d’informations !
25 février 2013
Les notions de sécurité sont souvent mal considérées. Difficiles à comprendre et appréhender, coûteuses à déployer et ayant des résultats parfois variables (mauvaise étude, cas d’usage particulier, …), la sécurité dans les technologies de l’information reste un domaine de niche dans lequel peu s’aventurent. Elle représente en effet un travail considérable… Mais dont l’absence peut mener à des résultats désastreux (vols de données sensibles, indisponibilité prolongée de service, …) ayant des répercutions souvent catastrophiques (coût financier, par exemple, mais pouvant aller jusqu’à la disparition pure et simple d’une entreprise selon les données volées par exemple).
Pourtant, et en se focalisant sur le domaine qui nous intéresse ici directement, il existe aujourd’hui des solutions de chiffrement de trafic IP standardisées et efficaces. Deux méthodes générales peuvent être listées :
- Symétrique : une unique clé est partagée et sert à la fois à chiffrer et déchiffrer le trafic.
- Asymétrique : chaque entité dispose de deux clés, l’une servant à chiffrer (clé publique) alors que l’autre permet de déchiffrer le trafic (clé privée).
Chiffrement symétrique
Le premier type est simple d’utilisation et d’implémentation. Il offre de plus d’excellentes performances lorsqu’il s’agit de chiffrer/déchiffrer du trafic, la même clé servant aux deux usages. Il est fréquemment mis en œuvre dans des installations de type SOHO (Simple Office, Home Office) et se retrouve dans des solutions « grand public » (par exemple dans les WiFi sécurisés en WPA-PSK ou Pre-Shared Key).

En pratique toutefois, il montre rapidement ses limites pour plusieurs raisons :
- La clé doit être échangée à un moment donné. Et cet échange peut être intercepté, rendant le chiffrement inutile…
- La clé est définie par un des participants, et n’est pas renouvelée automatiquement, la rendant plus vulnérable à des attaques par dictionnaire, par exemple.
Plus la clé symétrique est longue, plus ce second point est atténué. Toutefois, plus la clé est longue, plus le premier point peut devenir contraignant… Ce n’est donc pas une solution viable à long terme.
Chiffrement asymétrique et hybride
Le chiffrement asymétrique, de son côté, est sensiblement plus complexe (quatre clés au lieu d’une seule, chiffrement/déchiffrement bien plus coûteux en ressources, …). Contrairement au chiffrement symétrique, cette approche offre le meilleur niveau de sécurité grand public connu actuellement, proposant une théorique inviolabilité jamais contestée jusqu’à présent (sauf dans le cas de problèmes d’implémentation, liés souvent à une génération prévisible de nombres aléatoires).
Si la clé publique, comme son nom l’indique, peut être distribuée à n’importe qui (elle ne peut servir à rien d’autre qu’au chiffrement et à l’identification), la clé privée, elle, doit impérativement rester secrète sans quoi tout l’intérêt de cette technique disparaît. Toute personne en possession de cette clé peut en effet facilement usurper l’identité du possesseur originel.
A titre d’exemples, RSA (conçu en 1977 et nommée après ses inventeurs, R. Rivest, A. Shamir and L. Adleman) et DH (1976, également du nom de ses inventeurs, W. Diffie et M. Hellman) sont tous deux des algorithmes se reposant sur ce principe d’asymétrie. Les certificats standardisés x.509 représentent la forme la plus courante de distribution de clés publique/privée.
Son coût élevé en ressources pour chiffrer/déchiffrer le trafic ne lui permet malheureusement pas d’être utilisé pour chiffrer de grandes quantités de données. Des méthodes « hybrides » ont été créées afin de palier à ce problème et coupler les avantages du chiffrement symétrique et asymétrique. Le fonctionnement de cette approche est représenté ci-dessous de manière (très) simplifiée DON’T PANIC ! 😉

- Alice demande une connexion sécurisée avec Bob.
- Bob transmet, de manière non sécurisée, son certificat, à savoir sa clé publique. Le fait que le médium ne soit pas sécurisé n’est donc pas un problème ici, tout le monde pouvant demander l’accès à cette clé.
- Alice récupère la clé publique de Bob et authentifie celui-ci. La connexion est refusée si cette identité ne peut être vérifiée.
- Par des procédés cryptographiques dans lesquels nous n’allons pas nous engager ici (à base de très grands nombres premiers aléatoires que les deux entités s’échangent… Je vous passe les détails mais vous conseille cet excellent article publié sur Ars Technica [EN] très récemment), Alice génère une Pre-Master Key.
- Cette clé ainsi que la clé publique d’Alice sont transmises à Bob. Le secret de la Pre-Master Key doit être préservé pour assurer l’efficacité de la méthode. Alice possédant la clé publique de Bob, elle l’utilise pour chiffrer son message.
- A la réception du message chiffré, Bob utilise sa clé privée pour déchiffrer le message, chiffré avec sa clé publique par Alice. Il en extrait deux éléments : la clé publique d’Alice et, encore plus important, la Pre-Master Key.
- Bob authentifie Alice à l’aide de sa clé publique. Si l’identité est vérifiée correctement, la négociation est terminée. Ce message peut être transmis de manière sécurisée grâce à la clé publique d’Alice. Celle-ci utilise alors sa clé privée pour décoder le message.
- Dans le même temps, les deux parties génèrent la même clé maître (Master Key) finale via des procédés cryptographiques. De cette clé, ils peuvent en déduire une clé de session identique (et donc symétrique). Cette clé est régénérée régulièrement afin d’éviter les problèmes inhérents aux clés symétriques.
- Cette clé de session symétrique permet de chiffrer efficacement le trafic entre les deux entités, sans la surcharge imprimée par un chiffrement asymétrique.
Cette méthode prend avantage des deux approches : d’un côté, le chiffrement asymétrique permet, au travers d’un médium non sécurisé (Internet, …), de sécurisé les données échangées afin de générer dynamiquement, sans avoir besoin de l’échanger directement, une clé symétrique permettant de chiffrer un trafic important. Cette clé symétrique étant renouvelée régulièrement, elle ne peut être devinée facilement avec les moyens actuels.
Ce type de chiffrement, dit mutuel puisque chacun peut être authentifié à l’aide de son certificat, se retrouve généralement dans des applications nécessitant un niveau de sécurisation très pointu. Il est toutefois prévu que WebRTC, cette technologie dont nous avons déjà abordé dans ce blog précédemment (ici, là ou encore dans le cadre de notre formation WebRTC), chiffre le trafic temps-réel à l’aide de cette méthode via DTLS (Datagram Transport Layer Security), soit du TLS sur UDP.
Une version « allégée » de cette méthode est utilisée beaucoup plus couramment lors de l’accès à des sites Web sécurisés (une banque ou un site marchand, par exemple). Seul le serveur dispose dans ce cas d’un certificat, qui permet au client de certifier qu’il se connecte effectivement au bon site. Le client, lui, ne dispose pas de certificat, mais le fonctionnement reste globalement le même : la Pre-Master Key est toujours transmise (point 5) de manière sécurisée, le client disposant ici aussi de la clé publique du serveur, protégeant ainsi un des principaux secrets de la méthode. Une clé symétrique est générée de la même manière pour chiffrer la session entre le client et le serveur sécurisé.
Oui, mais…
Si ce chiffrement semble idéal en bien des points, il est judicieux de s’interroger sur les certificats en eux-mêmes : comment être sûr qu’un certificat appartient bien à une entité donnée ? Diverses méthodes existent, soit en faisant appel à une infrastructure centralisée (PKI ou Public Key Infrastructure), soit en utilisant un système décentralisé basé sur la création de réseaux de confiance, tel que le prône certaines technologies comme PGP (Pretty Good Privacy), mais également WebRTC !
Mais tout ceci est un sujet à part entière que nous aborderons prochainement dans un nouvel article ! So stay tuned !
Mise à jour (2013-03-01) :
Une erreur (récurrente) s’était glissée dans ce post. Le terme « chiffrage », s’il est accepté par l’académie française pour parler de ce sujet, n’est pas le terme français reconnu. « Chiffrement » doit être utilisé en lieu et place. Ces deux termes sont toutefois très proches, mais dans un souci de précision, la correction a été apportée à l’article. A noter que si « chiffrage » et « chiffrement » sont très proches, « cryptage » (et en particulier « décryptage ») a une toute autre signification, puisque ce terme est uniquement utilisé lorsqu’une personne n’ayant pas les bonnes clés tente de déchiffrer un message donné.
La terminologie dans le domaine de la sécurité : toute une histoire 😉
5 juin 2012
La transition entre IPv4 et IPv6 se rapproche toujours un peu plus, et il convient de se préparer à aborder cette transition au mieux. Le cadre le plus intéressant à considérer ici dans le monde de la ToIP (Telephony over IP) se repose sur l’utilisation du protocole SIP (Session Initiation Protocol), majoritairement utilisé à l’heure actuelle et en voie de devenir toujours plus important à l’avenir. Le déploiement de IPv6 se fera progressivement, et il y aura obligatoirement une période plus ou moins longue pendant laquelle IPv4 cohabitera avec IPv6. Si IPv6 n’apporte aucun réel changement par rapport à IPv4 dans le fonctionnement général des réseaux, ces deux protocoles sont néanmoins incompatibles directement, et il est nécessaires de pouvoir effectuer une transition de la manière la plus transparente possible.
(suite…)
5 juin 2012
Après avoir traité des approches hybrides (tunneling) puis compressives (mapping), ce dernier article va discuter du dernier type de options actuellement disponibles, sous la forme de solutions translatives allant faire la traduction entre les deux versions du protocole IP (protocol translation).
(suite…)
5 juin 2012
Au cours de la première partie, nous avions commencé à aborder les différentes options de déploiement IPv6 disponibles pour les opérateurs avec les méthodes de type hybride/tunneling. Dans le présent article, nous allons poursuivre cette étude en observant une approche quelque peu différente, puisque tentant ici de rationaliser l’usage des adresses IPv4 afin de limiter l’hémorragie et de pouvoir continuer à fournir un service IPv4 dans les années à venir tout en migrant progressivement vers IPv6.
Certaines de ces solutions, nous allons le voir, essaient de coupler l’aspect préservation avec l’aspect migration, mais il est souvent nécessaire de combiner ces approches avec d’autres protocoles de transition afin d’avoir et une solution de migration vers IPv6, et une solution de préservation d’adresses IPv4
(suite…)
5 juin 2012
Nous l’avons vu dans cet article sur les solutions à disposition des clients afin d’obtenir une connectivité IPv6, mais il s’avère désormais que la gestion des différentes problématiques, relative tant à la pénurie d’adresses IPv4 qu’à la migration vers IPv6, vont incomber en grande partie aux fournisseurs d’accès.
Les opérateurs disposent d’un large choix de solution, leur permettant de sélectionner la meilleure approche possible au regard de leur infrastructure et de l’approche qu’ils envisagent pour aborder ces problématiques. Au regard du nombre d’options possibles, nous allons exposer ces différentes solutions au travers de trois articles successifs, en abordant en premier lieu les solutions hybrides (tunneling) avant de traiter successivement les approches compressives et translatives.
(suite…)
5 juin 2012
Le risque de pénurie d’adresses IPv4 devient de plus en plus présent avec les mois qui s’écoulent. Des solutions temporaires avaient été apportées avec les NAT, mais il est désormais essentiel de préparer une migration la plus rapide possible vers IPv6 tout en devant gérer cette pénurie, ce qui ne facilite en rien le travail de transition IPv4-IPv6.
De (très) nombreuses solutions ont été imaginées et proposées ces dernières années afin de tenter d’apporter une solution efficace et (relativement) facile à mettre en œuvre afin d’assurer cette transition. Ce choix est une bonne nouvelle puisqu’il va permettre de choisir la méthode la plus appropriée au cas de figure considéré. Ce qui est malheureusement aussi une mauvaise nouvelle puisque cette débauche de solutions engendre un problème de taille : quelles sont les solutions optimales et pour quels cas de figure ?
Ces solutions peuvent être classées en deux écoles différentes : soit la transition est assurée majoritairement au niveau du client, soit cette transition est effectuée par le fournisseur d’accès. Nous commencerons par décrire les approches possibles au niveau des utilisateurs finaux (clients) avant d’aborder, dans un prochain article, les mécanismes offerts aux fournisseurs d’accès.
(suite…)
5 juin 2012
Nous avons précédemment discuté des notions de syntaxe et de classification des adresses IPv6. Il reste toutefois encore un sujet à aborder dans ce domaine, la question de l’adressage en lui-même. Il ne sera pas ici question d’effectuer un plan d’adressage, mais bel et bien des contraintes entourant la distribution et la confection des adresses IPv6 pour chaque entité du réseau.
(suite…)
5 juin 2012
Depuis les débuts du protocole Internet (Internet Protocol ou IP), la plage complète d’adresses ont toujours été classifiées dans différents rôles et usages. Ces rôles ont évolués au fil du temps, et ont été remis à jour avec l’arrivée d’IPv6.
(suite…)
5 juin 2012
Les adresses IP majoritairement utilisées actuellement (IPv4) sont particulièrement bien connues et relativement faciles à retenir et utiliser. IPv6 introduit toutefois une certaine complexité dans ces adresses, celles-ci étant sensiblement plus longues, mais aussi devant respecter des règles stricts que nous allons détailler au sein de cet article.
(suite…)
5 juin 2012
Le protocole IP, ou Internet Protocol, permet la création d’un réseau offrant une connectivité entre des entités distantes au sein d’un réseau étendu, voire global (Internet). Ce protocole se repose sur l’utilisation d’adresses afin de localiser les terminaux et entités sur le réseau. Ces adresses s’apparentent, dans leur usage, aux adresses attribuées à chaque lieu de résidence et habitation : sans cette adresse, il devient difficile, voire impossible, de recevoir les services courants (courrier, livraisons …). En théorie, les adresses du protocole IP permettent un usage similaire, définissant une adresse unique pour chaque entité sur le réseau, et permettant ainsi à cette entité de réclamer des services ou de pouvoir être contactée. (suite…)
5 juin 2012
Dernier article de notre série relative à la traversée de NAT, nous ne pouvions pas ne pas discuter un peu plus en détail de l’impact qu’aura probablement, à terme, le protocole Internet (Internet Protocol) dans sa version 6.
(suite…)
5 juin 2012
Au sein de notre série d’articles relatifs à la traversée de NAT, nous avons abordé, dans cet autre billet, une approche courante envisagée par les acteurs de l’industrie : les ALG et SBC. Nous en avions conclu que cette approche, si elle n’est pas dénuée de bon sens, est sujette principalement à deux gros problèmes :
- Les implémentations « grand public » des ALG sont le plus souvent lacunaires, engendrant plus de problèmes qu’elles en résolvent.
- Les SBC requièrent des compétences et connaissances coûteuses les réservant à certains types d’environnements.
Il était par conséquent nécessaire de combler le vide qui caractérisa la traversée de NAT pendant longtemps, avant que les standards commencent à se développer sérieusement. Des approches ont été envisagées par les différentes implémentation de serveurs SIP au fil du temps, que ce soit de soft switch/IPBX complets (Asterisk, FreeSWITCH) ou de « simples » proxys. Nous allons nous attarder ici particulièrement sur ce dernier cas, et en particulier sur OpenSIPS, un proxy SIP particulièrement performant, modulaire et évolutif.
(suite…)
5 juin 2012
Lors de nos différents articles relatifs aux solutions de traversée de NAT, nous avons détaillés les approches proposées par l’IETF (received/rport, SIP-OUTBOUND, STUN, TURN, ICE) et étant par conséquent normalisées. Ces protocoles, s’ils offrent ensemble une approche complète, efficace et évolutive, sont malheureusement pour la plupart très récents : les acteurs de l’industrie (opérateurs, intégrateurs, …) ont dû trouver des solutions qui leur ouvraient l’utilisation de SIP/RTP dans le cadre de la voix sur IP. Plusieurs solutions existent à ce niveau, mais la plus commune à l’heure actuelle est caractérisée par les ALG (Application Level Gateways) et, de manière plus spécifique, les SBC (Session Border Controllers).
(suite…)
5 juin 2012
Dans notre précédent article, nous avons commencé à discuter des mécanismes régissant le protocole ICE, notamment lorsque le processus s’initie : récupération des couples adresse/port par lesquelles une extrémité sera en mesure d’émettre une requête, puis les échanger avec la partie distante jusqu’à ce que l’un comme l’autre disposent de l’ensemble des informations. Cette étape est essentielle, mais, comme dans la réalité, lorsque des candidats sont définis, il faut encore, par la suite, les élire de manière à définir lequel sera choisi au final. Ce second article sur ICE traite de ce sujet en particulier : la sélection d’un candidat au travers de tests de connectivité.
(suite…)
5 juin 2012
ICE, ou Interactive Connectivity Establishment, apporte un niveau d’abstraction aux protocoles STUN et TURN décrits dans les articles précédents (respectivement ici et là). Alors que beaucoup de solutions, et STUN et TURN en font partie lorsqu’ils sont utilisés indépendamment, plaçaient l’intelligence au niveau des serveurs (ceux-ci détenant le maximum d’informations), ICE fait le pari inverse : intégrer cette intelligence au niveau du client. En effet, comme le discutera cet article ainsi que le suivant, les serveurs ne servent désormais que d’outils permettant au client d’apprendre et de connaître son environnement.
(suite…)
5 juin 2012
Lors de notre précédent article, nous avions discuté de STUN, dont les fonctionnalités offrent déjà une gamme de services intéressantes. Il avait cependant été question que cette traversée de NAT, si elle est efficace, n’est pas exhaustive, puisque seuls les NAT dont les associations sont créées indépendamment de la destination sont supportés. Malheureusement, beaucoup de NAT à l’heure actuelle ne fonctionnent pas de cette manière, étant bien souvent des NAT symétriques ou, plus manière plus générique, dépendants de la destination. TURN (Traversal Using Relays around NAT) a été étudié comme un extension à STUN venant particulièrement combler ce problème en proposant une approche se basant sur un serveur relai servant de pont entre les deux parties.
(suite…)
5 juin 2012
Dans cet article, nous discutions des méthodes permettant la traversée de NAT des messages SIP, tant pour les réponses que les requêtes. Nous avons mentionné une méthode permettant de maintenir les différentes associations au niveau du NAT valides en utilisant le protocole STUN. Toutefois, qu’est-ce que STUN et comment fonctionne-t-il ?
(suite…)
5 juin 2012
Lors de notre dernière incursion dans les méandres des NAT en VoIP, nous avions discuté de la méthode envisagée pour permettre aux réponses SIP (200 OK par exemple) d’atteindre leur cible. Il avait toutefois été noté qu’il était, en théorie, impossible de réutiliser ces informations dans le but d’acheminer des requêtes SIP (INVITE par exemple). L’IETF a de ce fait imaginé une méthode spécifique permettant aux requêtes distantes de contacter un client situé derrière un NAT : SIP-OUTBOUND. Alors que les attributs received et rport modifient les entêtes Via, cette méthode s’occupe d’altérer les informations contenues dans le Contact afin de pouvoir acheminer la requête correctement. Mais si elle se limitait à ceci, elle n’aurait que peu d’intérêts.
(suite…)
5 juin 2012
Dans la continuité des articles relatifs au NAT en ToIP publiés précédemment (introduction sur les NAT et terminologie des NAT), examinons tout d’abord le problème du point de vue de SIP, ainsi que les méthodes de résolution pouvant s’appliquer.
Lorsque SIP (Session Initiation Protocol) a été initialement spécifié aux alentours des années 2000 (mars 1999 pour être exact), il est intéressant de noter que, si les NAT existaient déjà et étaient déployés de manière conséquente, il n’a jamais été question de leur traversée par le protocole. De l’aveu même de ses auteurs, le protocole n’est pas pensé pour géré le NAT :
« A host behind a network address translator (NAT) or firewall may not be able to insert a network address into the Via header that can be reached by the next hop beyond the NAT. Use of the received attribute allows SIP requests to traverse NAT’s which only modify the source IP address. NAT’s which modify port numbers, called Network Address Port Translator’s (NAPT) will not properly pass SIP when transported on UDP, in which case an application layer gateway is required. When run over TCP, SIP stands a better chance of traversing NAT’s, since its behavior is similar to HTTP in this case (but of course on different ports). »
Pire encore, la seule fonctionnalité qui lui permettrait de gérer ce problème partiellement s’avère lacunaire, puisqu’elle ne prend en considération que l’adresse et non le port. Mais pourquoi SIP a-t-il autant de problèmes à traverser les NAT ? Tout simplement car SIP, en tant que protocole applicatif, transport ses propres adresses et ports au sein de ses messages de manière à établir des sessions entre deux entités. Toutefois voici ce qui se passe réellement lorsqu’une requête SIP traverse un NAT :

Lorsque le client émet une requête à destination de son proxy SIP (1), il forme son message SIP en utilisant les adresses et ports dont il a connaissance, c’est-à-dire des adresses privées, en règle générale. Ces informations correspondent pour le moment aux entêtes TCP/IP permettant le routage des paquets vers leur destination. Toutefois, lorsque le message va avoir traversé le NAT (2), ce dernier va modifier les entêtes TCP/IP des paquets afin que les réponses puissent aboutir et pointer vers l’adresse, non plus du client (privée et inaccessible depuis l’extérieure), mais publique. Malheureusement, le NAT ne fonctionnant qu’au niveau du réseau (TCP/IP), il n’est pas en mesure de modifier le contenu du message SIP en tant que tel. De ce fait, aucune réponse SIP ne pourra aboutir correctement.
Dès lors, comment procéder à la résolution de ce problème au niveau SIP ? Les auteurs de la spécification originelle avaient envisagé une gestion lacunaire des réponses SIP (par l’entête Via) au travers d’un attribut received. Lorsqu’un serveur reçoit une requête, il définit cet attribut en y associant l’adresse par laquelle la requête a été émise. Puisqu’il réceptionne la requête modifiée du NAT, il est en mesure de connaître l’adresse à laquelle il doit envoyer les réponses à la requête. Toutefois, comme le suggère notre précédent post, il manque une composante importante afin que les réponses soient acheminées correctement : le port !
Ce manque a été comblé en 2003 avec l’introduction d’un nouveau paramètre au champ Via : puisque l’adresse est récupérée dans un attribut received, pourquoi ne pas stocker le port de manière similaire. Cette extension au protocole SIP rajoute par conséquent un attribut rport (pour received port) qui permet de stocker, en plus de l’adresse, le port par lequel la requête a été émise du NAT. L’ajout de cette fonctionnalité permet l’introduction du concept de réponse symétrique (symmetric response) qui réutilise systématiquement le même couple adresse/port pour émettre et recevoir.
Client SIP :
INVITE sip:ua2@nexcom.fr SIP/2.0
Via: SIP/2.0/UDP 10.0.0.1:4540;rport;branch=Kkjshdyff
Proxy SIP :
INVITE sip:ua2@nexcom.fr SIP/2.0
Via: SIP/2.0/UDP proxy.nexcom.fr;branch=Kkjsh77
Via: SIP/2.0/UDP 10.0.0.1:4540;received=123.4.56.78;rport=9988
;branch=Kkjshdyff
Malheureusement, ces paramètres ne s’appliquent qu’aux réponses (par exemple 180 Ringing), mais ne permettent pas, par leur conception, d’être utilisés en dehors de ce cadre, notamment pour acheminer des requêtes venant d’un utilisateur distant souhaitant contacter le client. Comme nous en discuterons, certaines implémentations ont contourné ce problème en stockant par exemple ces valeurs de manière persistante afin de les réutiliser dans d’autres cas de figures (ce qui est en soi relativement malin). Toutefois, ce genre de solution ne respectent pas le cadre classique des standards, qui définissent une méthode spécifique pour ce cas précis, et qui sera détaillée prochainement dans un nouvel article : la spécification SIP-OUTBOUND !
Stay tuned !
27 mars 2012
Nous avons présenté dans notre précédent article les principaux concepts et l’architecture générale de RTCWeb. Nous abordons maintenant dans ce billet, l’API WebRTC, qui va permettre aux applications s’exécutant dans les navigateurs Web d’exploiter toutes ces fonctions. Cette API, encore à l’état de working draft, est développée par le W3C (World Wide Web Consortium) et utilise de nombreux éléments introduits en HTML5 (balise video par exemple).
Notre objectif dans cet article est de décrire le fonctionnement global de l’établissement de session entre deux navigateurs. L’implémentation d’une telle fonction repose sur 3 phases principales: l’acquisition des ressources audio/vidéo dans le navigateur de l’émetteur, la transmission de ces flux sur le réseau et le rendu sur le navigateur du récepteur. Nous décrivons ainsi les deux principales primitives WebRTC permettant d’atteindre ce but: la Stream API qui permet la manipulation de ressources multimédias et l’interface PeerConnection qui assure la communication à travers le réseau. Nous présentons les principes généraux de ces deux primitives sans rentrer, à ce stade, dans les détails de l’API car ces derniers ne sont pas stabilisés et vont encore faire l’objet de nombreuses modifications.
Stream API
La Stream API, et en particulier son objet MediaStream, est au cœur du fonctionnement de WebRTC. Toute la partie multimédia passe par elle, quelle que soit la source et la destination du trafic.

Un flux média (media stream en anglais) contient et traite les pistes audio et vidéo. Ces flux peuvent provenir de différentes sources (locales ou distantes), et sont émis à des destinations variables (locales ou distantes également). Au sein de cette interface, seul l’objet MediaStream reste immuable quelle que soit le cas de figure considéré.
Les différentes étapes illustrées sur la figure ci-dessus sont les suivantes:
1. Construction de l’object MediaStream
L’objet MediaStream prend en paramètre soit une connexion distante (PeerConnection, voir ci-après), soit un objet LocalMediaStream ayant accès aux ressources locales du terminal. Ces accès, pour des raisons de sécurité, doivent être explicitement donnés par l’utilisateur au cas par cas, via l’usage de boutons (« Diffuser ma vidéo » pour autoriser le flux vidéo par exemple) ou par des préférences dédiées à chaque page et gérées par le navigateur. La fonction getUserMedia() récupère, simultanément ou séparément (il est possible de l’appeler plusieurs fois), les différentes sources afin de les traiter par la suite.
2. Sources locales
Ces ressources peuvent émaner de différentes origines, notamment d’équipements de capture en temps réel (microphone, webcam, caméra …) ou de fichiers locaux au terminal. Le support de ces différentes sources est assurée grâce aux nouvelles fonctionnalités offertes par HTML5 (File API, Media Capture).
3. Gestion des différents flux
Un MediaStreamTrack est créé pour chacun des flux, audio ou vidéo. Puisqu’il peut exister de multiples flux simultanés (plusieurs microphones distincts par exemple), ceux-ci sont stockés au sein de listes de type MediaStreamTrackList. Ces listes sont utilisées pour créer le flux média (MediaStream). Il est ici intéressant de noter plusieurs points :
- Grâce à ces listes, l’objet MediaStream est dynamique. Il devient en effet possible d’ajouter et de retirer à la volée des flux multimédias sans avoir besoin de recréer un nouvel objet (fonction add() de l’objet MediaStreamTrackList).
- Les pistes audio peuvent contenir un nombre variables de canaux (mono, stéréo, 5.1 …), permettant leur utilisation dans de multiples situations différentes. Ces canaux sont les plus petites unités d’un MediaStream.
4. Utilisation du MediaStream
Cet objet MediaStream peut ensuite être utilisé dans divers cas de figures :
- le flux peut être directement affiché dans le navigateur local, ce qui peut servir à afficher le retour d’une webcam locale ou le flux en provenance d’un tiers via un objet PeerConnection en entrée;
- les flux peuvent être enregistrés dans des fichiers locaux;
- les flux peuvent être envoyés à un tiers à l’aide d’un objet PeerConnection, ce qui est est l’objectif même de WebRTC.
La pratique veut que ces objets MediaStream disposent d’un URL pour l’objet binaire qu’il représente (BLOB ou Binary Large OBject). La fonction createObjectURL crée cet URL. Les données de l’objet que cet URL représente doivent être compréhensibles directement par les éléments HTML5 audio ou video.
Dernier point intéressant au sujet de cette Stream API, il est possible d’adjoindre à ce schéma général un objet MediaStreamRecorder permettant, comme son nom le laisse suggérer, d’enregistrer en temps réel les flux audio/vidéo. Cet enregistrement est représenté sous la forme d’un BLOB. Cet enregistreur doit être capable de gérer efficacement l’ajout ou la suppression de MediaStreamTrack du flux multimédia.
Pour plus d’informations sur la gestion des fichiers et des BLOB, se référer à la File API.
La figure ci-dessous illustre un cas d’usage typique du fonctionnement de MediaStream. La fonction getUserMedia() (1), déclenchée par un bouton, autorise l’accès aux différents équipements (microphone, webcam …) (2) afin d’en récupérer les flux audio/vidéo. Ces LocalMediaStream ou MediaStreamTrack sont traité par la fonction appelée (callback) en cas de succès, afin de les ajouter aux MediaStreamTrackList d’un objet MediaStream, créant effectivement le flux média. Celui-ci peut ensuite être ajouté à une connexion sortante (4) PeerConnection afin de transmettre le flux à un destinataire.

PeerConnection API
Si l’objet MediaStream discuté précédemment est incontournable pour la manipulation des flux multimédias, l’objet PeerConnection de son côté est primordial pour l’établissement d’une connexion, de manière transparente, entre deux entités RTCWeb. Définie au sein de la même spécification que la Stream API, cette API risque d’être altérée en profondeur dans les mois à venir puisque l’IETF est en train de définir un framework d’établissement de session pour RTCWeb/WebRTC (JSEP ou Javascript Session Establishment Protocol actuellement en draft00) qui va avoir un impact certain sur les routines de l’objet PeerConnection. Partant de ce constat, nous faisons ici le choix de n’énoncer que les éléments généraux qui seront probablement traités par l’objet, d’une manière ou d’une autre.
L’objet PeerConnection gère l’ensemble de l’établissement de connexion avec la partie distante. Actuellement, comme décrit dans la figure ci-dessus, lors de sa création, il est possible de remarquer qu’il prend deux paramètres qui traitent de deux aspects bien distincts :
- Son premier paramètre spécifie un serveur STUN/TURN pour la traversée de NAT des flux multimédias qui systématiquement tentée par l’usage d’ICE.
- Son second paramètre définit la fonction à appeler (callback) pour envoyer des messages de signalisation. Il est dès lors possible de manipuler et personnaliser les messages envoyés au destinataire via cette fonction.
La signaling callback passée en second paramètre permet de générer les messages de signalisation, nécessaires pour échanger les informations de connexion, grâce à SDP. Le protocole de signalisation en lui-même (SIP, Jabber/Jingle, propriétaire) est laissé au libre choix de l’implémentation. Afin de permettre l’utilisation de SIP dans ce cadre, un draft est en discussion au sein de l’IETF afin d’ajouter un transport de type WebSocket au protocole SIP.
Encore peu utilisé au sein de la VoIP actuellement, le protocole ICE va gagner, avec ces implémentations, ses lettres de noblesse puisqu’il prend ici une place centrale dans la traversée des NAT des flux multimédias. Si les détails de son fonctionnement sortent du cadre de cet article, rappelons toutefois qu’il a pour objectif de négocier automatiquement et de manière totalement transparente la connexion en effectuant de multiples tests de connectivité entre les deux terminaux (ici, les navigateurs) après avoir récupéré son adresse publique et une éventuelle adresse relai grâce respectivement au serveur STUN ou TURN passé en paramètre. L’efficacité de ce protocole n’est plus à prouver et son déploiement dans ce cadre renforce encore la facilité d’accès par les utilisateurs finaux aux applications développées sur cette base.
Démonstration basique
Afin d’illustrer cette API, nous vous présentons ci-dessous un exemple, très simple, d’utilisation de l’objet MediaStream, sans connexion à un hôte distant, mais en affichant le retour direct du flux d’une webcam connectée sur votre ordinateur. Seule une démonstration basique est proposée ici pour plusieurs raisons :
- La spécification est encore au stade de brouillon fonctionnel (working draft) et est donc fortement susceptible de changer à l’avenir. Notamment, l’objet PeerConnection est actuellement en pleine refonte, mais il est aussi probable que des modifications soient apportées à MediaStream également.
- Les implémentations sont expérimentales et souvent instables. En l’état ici, seuls les navigateurs expérimentaux Opera Labs Camera et Google Chrome Canary sont supportés. Si vous testez cette page avec ces navigateurs, ils doivent vous demander si vous souhaitez autoriser ou non l’usage de la webcam. A noter que Chrome Canary nécessite une configuration manuelle à l’adresse chrome://flags afin d’activer l’option MediaStream

Note: nous ne pouvons garantir un fonctionnement optimal de cette démonstration, ces fonctions étant expérimentales et susceptibles de changements à tout moment dans les implémentations.
Si cette démonstration est extrêmement basique, elle donne un aperçu de ce que ces deux APIs, relativement simples, peuvent offrir lorsque les implémentations seront finalisées et massivement déployées (téléphonie/visiophonie à partir d’un simple navigateur de manière standardisée, …). Les progrès réalisés au cours de ces derniers mois sont impressionnants et présagent du meilleur pour RTCWeb et son API, WebRTC. A suivre …
25 janvier 2012
Comme nous en discutions dans notre précédent post, l’introduction des NAT dans les réseaux actuels, si elle a résolu, du moins temporairement, le problème de la pénurie d’adresses IPv4, a par la même occasion engendré de nouvelles contraintes techniques pour un certain type de trafic, et plus particulièrement, en ce qui nous intéresse ici, en téléphonie sur IP (ToIP ou Telephony over IP). La prise en compte de ces nouvelles contraintes se repose sur la détermination du type de NAT que le trafic doit traverser. En effet, par un manque de cadre et d’orientation lors de leurs conceptions, leurs implémentations s’avèrent très disparates. Ce post vous décrit les différentes méthodes existantes permettant leur classification.
(suite…)
19 janvier 2012
Le projet WebRTC vient d’annoncer la disponibilité dans Chrome d’une première implémentation de l’API WebRTC. Ce projet s’intègre dans la récente initiative RTCWeb visant à intégrer des fonctions de communication temps-réel dans les navigateurs Web. Nous profitons de cette occasion pour présenter les objectifs et l’architecture générale de RTCWeb.
Objectifs de RTCweb
Les fonctions offertes par le navigateur Web sont de plus en plus étendues et lui permettent de déborder de son rôle historique d’affichage de pages Web pour devenir un véritable environnement d’exécution d’applications riches. Cette tendance a ainsi été popularisée par des services tels que GMail et la suite Google Apps.
Les fonctions multimédias et de communications interactives ont jusqu’à récemment été rendues possibles uniquement par l’utilisation de plugins propriétaires tels que Flash Player (les objets de type ActiveX, Java ou autres n’ayant eu qu’un succès très limité dans ce cadre) qui a permis notamment le développement massif de la vidéo Web avec des services comme YouTube. Il devient maintenant possible de téléphoner à partir d’une page Web intégrant une applet Flash (voir par exemple http://call.nexcom.fr).
Le développement de la technologie HTML5 qui intègre une multitude de nouvelles fonctions permet maintenant de standardiser ces fonctionnalités. Ainsi les services de diffusions vidéo (Youtube par exemple) ou de partage de documents (tel Slideshare) sont engagés dans une logique de remplacement de fonctions auparavant développées en Flash par du HTML5. Ces fonctions restent pour l’instant relativement simples et sans interactions complexes mais l’évolution rapide des standards permet maintenant d’envisager le développement d’applications Web plus sophistiquées.
L’initiative RTCWeb (Real Time Collaboration on the Web) vise ainsi à standardiser l’infrastructure implémentée au sein des navigateurs Web permettant d’établir des communications audio et vidéo, directes, interactives et en temps-réel, entre des utilisateurs Web.
Cet effort se déroule au sein de deux groupes de travail:
Ces deux groupes ont démarré depuis peu et de nombreux points restent ouverts et sujets à (vives) discussions, le sujet intéressant les plus grands acteurs de l’Internet (Google, Cisco, Mozilla, Apple, Skype …). Ainsi, nous décrivons par la suite les grands principes de RTCWeb sans rentrer dans les détails techniques susceptibles d’évoluer. Nous reviendrons plus tard sur ces derniers ainsi que l’API WebRTC avec de nouveaux articles quand ces points seront plus aboutis.
Architecture générale RTCWeb
RTCWeb ne vise pas à intégrer dans le navigateur des services de haut niveau de type softphone. L’idée est plutôt de spécifier les primitives nécessaires à la mise en oeuvre de tels service en conjonction avec des serveurs externes. En particulier, l’objectif est de permettre à ce qu’une application Javascript intégrée au sein d’une page Web et s’exécutant dans un navigateur standard puisse établir une communication utilisant des canaux audio, vidéos et de données et ce, sans contrainte sur le type de service fourni par l’application Web.
Un service de type softphone pourra ainsi être fourni par une application Javascript implémentant un widget téléphone et mettant en oeuvre un protocole de signalisation basé par exemple sur les WebSockets. Cette application utilisera les primitives RTCWeb pour capturer les flux audio et vidéo de la webcam, les encoder et les transmettre au correspondant.
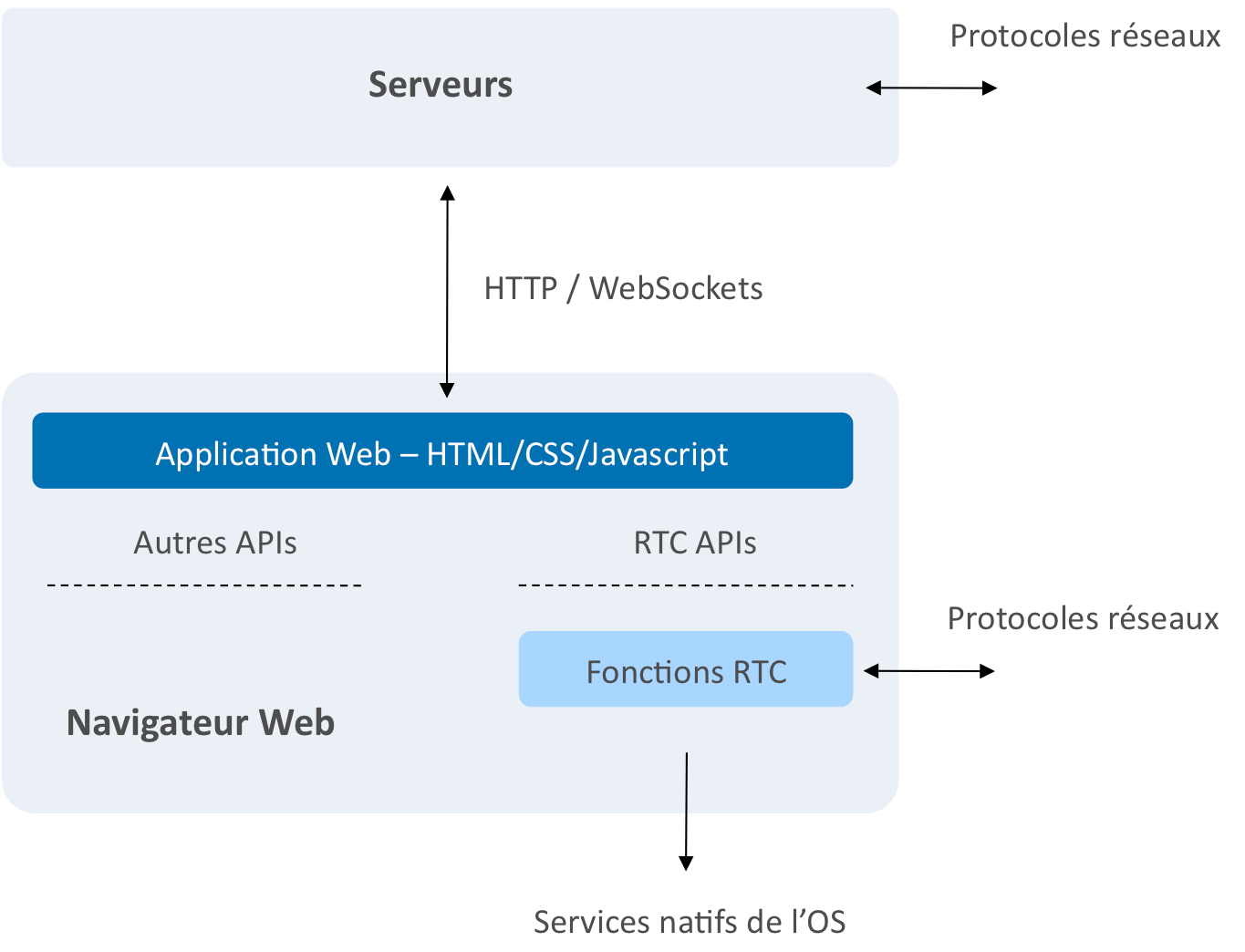
Le schéma suivant illustre une utilisation typique de RTCWeb. Il est important de noter qu’il existe un lien media direct entre navigateurs et basé sur les protocoles définis au sein de RTCWeb. En revanche la signalisation emprunte un chemin qui peut être plus complexe et utilise des protocoles qui peuvent être propriétaires. Dans cet exemple, la signalisation utilise la connexion HTTP/Web Sockets entre le navigateur et le serveur Web et est spécifique à l’application Web délivrée par le serveur et s’exécutant au sein du navigateur. S’il y a un besoin d’interopabilité, la communication entre serveurs Web sera purement du ressort applicatif et pourra utiliser un protocole standard tel que SIP.

Il reste maintenant à définir les détails de ces différentes primitives et protocoles. Les discussions portent en particulier sur les points suivants:
- format des flux: quels sont les codecs offerts par le navigateur ? Doit-on spécifier une liste de codecs communs et toujours disponibles ?
- transport des données média: de nombreuses discussions portent sur le choix de RTP/SRTP, SRTP doit-il être imposé ou disponible en option ? Pour la gestion de la connectivité, ICE sera probablement utilisé.
- session de contrôle: doit-on réutiliser un protocole tel que SIP ou XMPP ou laisser cette partie sous le contrôle de l’application. Un consensus s’est dégagé sur cette dernière possibilité afin d’être le plus ouvert et flexible possible, il est ainsi probable que l’on verra apparaître des librairies Javascript implémentant SIP ou des protocoles simplifiés propriétaires. Dans tous les cas, quel modèle utiliser pour la négociation des formats média (SDP, autre …) ?
Le prochain article de cette série sera consacré à l’étude de l’API WebRTC, qui permet à l’application Javascript d’accéder à toutes ces primitives et de construire ainsi une application tirant parti de ces nouvelles fonctions HTML5.
16 janvier 2012
LTE (Long Term Evolution) constitue l’évolution 4G des réseaux de télécommunications mobiles et offrira notamment des débits mobiles beaucoup plus élevés que les réseaux actuels. Le réseau EPS (il convient de parler plutôt de réseau EPS, Evolved Packet System, le terme LTE désignant plutôt l’interface radio entre le mobile et le réseau mobile 4G) présente la particularité par rapport aux précédents réseaux mobiles 2G/3G de ne fournir qu’un service PS (Packet Service) de données alors que les réseaux 2G/3G offrent à la fois des services de type CS (Circuit Service) pour la voix et de type PS pour les données
Le réseau EPS ne propose ainsi que l’accès aux réseaux de données PDN (Packet Data Network) et tous les services devront ainsi être ainsi être conçus au dessus d’IP y compris les services traditionnels tels que la voix ou les SMS. Cela constitue donc une évolution majeure et les opérateurs devront déployer de nouveaux systèmes afin de continuer de fournir un service de voix sur les réseaux mobiles 4G. Pour cela, plusieurs solutions ont été imaginées.
CSFB (Circuit Switched FallBack)
Cette première solution consiste tout simplement à continuer d’utiliser le réseau 2G/3G pour le service téléphonique et à réserver le réseau 4G pour le service de transmission de données. Avec ce principe, le terminal mobile est connecté soit au réseau actuel GSM/UMTS soit au réseau LTE selon l’application qu’il utilise. Un échange de signalisation entre d’une part le coeur de réseau NSS (Network Sub System) et d’autre part le coeur de réseau EPC (Evolved Packet Core) du réseau 4G est alors nécessaire afin que le mobile puisse basculer vers le réseau 2G/3G lorsqu’étant connecté au réseau LTE, il reçoit ou désire émettre un appel téléphonique. S’il souhaite conserver ses communications données en cours, il est également nécessaire de basculer le mode PS établi avec le réseau 4G vers le mode PS sur le réseau 2G/3G.

Cette solution offre l’avantage de se baser sur des technologies existantes et éprouvées mais présente cependant plusieurs inconvénients:
- le temps de bascule entre les réseaux 4G et 2G/3G est significatif (de l’ordre de quelques secondes en moyenne) ce qui, en terme d’expérience utilisateur, n’est guère satisfaisant et l’on voit mal les premiers utilisateurs de LTE, probablement assez technophiles et dotés de smartphones les plus récents, accepter une telle régression.
- les transferts de données sont également perturbés durant la bascule ce qui, à l’heure des téléphones multitâches avec de nombreuses applications s’exécutant en tâche de fond, devra s’effectuer le plus rapidement possible afin de limiter l’impact en terme d’usage
- ce modèle s’intègre mal avec des perpectives de développements de nouveaux services en isolant la voix sur des anciennes technologies sans possibilité d’évolution. Il serait ainsi impossible par exemple, de proposer des services combinant voix et données en tirant profit du débit 4G (conférence, collaboration, jeux …).
Il s’agit là des principaux écueils du CSFB qui souffre en outre d’autres insuffisances (mauvaise intégration avec de potentielles femtocells LTE, mauvaise occupation de la bande radio …).
En résumé, le CSFB offre l’avantage de permettre une réutilisation complète de l’infrastructure existante (réseau, services, systèmes de facturation ..) en ne nécessitant que quelques mises à jours mineures. Cependant il s’agit là d’une solution permettant plus de prolonger la vie du réseau 2G/3G existant que de tirer profit de l’introduction de la 4G, ce qui risque de réduire fortement l’intérêt de déployer cette nouvelle technologie.
Un mécanisme assez similaire consiste à se connecter à la fois aux réseaux 2G/3G et 4G, mais de façon simultanée afin d’éviter la phase de bascule radio. Cette approche, connue sous le nom de SVLTE (Simultaneous Voice and LTE), a également le mérite de ne pas nécessiter de modifications dans le réseau mais conduit à une plus grande complexité du téléphone ainsi qu’une consommation énergétique accrue. Des terminaux utilisant ce système sont déjà disponibles en CDMA/LTE (pas encore en GSM/UMTS/LTE).
VoLGA (Voice Over LTE via Generic Access)
Cette seconde solution permet également de réutiliser l’infrastructure voix existante mais de manière un peu plus évoluée. Elle consiste à connecter le réseau EPS au coeur de réseau NSS qui fournit le service téléphonique 2G/3G par l’intermédiaire d’une passerelle VANC (VoLGA Access Network Controller). La signalisation 2G/3G de la téléphonie est ainsi réutilisée mais est transportée sur le réseau de données 4G en étant encapsulée au sein de paquets IP. Le réseau EPS joue alors le rôle de réseau d’accès au même titre que le BSS (Base Station Sub-system) du réseau 2G ou l’UTRAN (UMTS TRAnsport Network) du réseau 3G.

Cette solution présente l’avantage de n’apporter aucune modification tant au niveau du réseau EPS que du cœur de réseau NSS. Par contre, le mobile doit intégrer des adaptations pour le transport, sur le réseau 4G, de la signalisation NAS (Non Access Stratum) échangée entre le mobile et le réseau NSS.
Ce principe est déjà utilisé au sein de l’UMA (Unlicensed Mobile Access) qui permet de connecter des terminaux WiFi aux réseaux 2G / 3G. L’UMA est notamment mis en oeuvre dans l’offre Unik d’Orange qui permet d’accéder aux services 2G/3G sur son téléphone mobile à travers un réseau WiFi.
Comme le CSFB, VoLGA permet de réutiliser l’infrastructure existante, ce qui assure un déploiement rapide ainsi qu’une transparence complète du réseau vis-à-vis des services téléphoniques. De plus, VoLGA ne souffre pas des défauts majeurs de CSFB en assurant un accès simultané aux services voix 2G/3G et données LTE. Au niveau du réseau, VoLGA ne nécessite que le déploiement de quelques nouveaux éléments (VANC principalement). Le terminal, en revanche, devra également intégrer cette nouvelle technologie afin d’être en mesure d’encapsuler la téléphonie 2G/3G dans des paquets IP.
Le support de VoLGA dans le terminal constitue le principal obstacle à son adoption car cela nécessite un support fort des fournisseurs de mobiles pour une technologie de transition qui n’a pas vocation à être utilisée sur le long-terme. Ce point est de plus exacerbé par le fait qu’il s’agit d’une technologie non adoptée par le 3GPP, l’organisme qui est en charge des spécifications GSM et LTE. Par ailleurs, VoLGA, comme CSFB, ne permet pas de véritables services de convergence car les réseaux gérant la voix et les données restent séparés.
IMS (IP Multimedia Subsystem)
La dernière solution, qui est présentée comme la solution cible à long terme est celle de la mise en oeuvre de l’IMS, qui est le réseau multimédia IP spécifié par le 3GPP. Ce réseau, extérieur au réseau 4G, permet de supporter tous types de services et de réseaux d’accès. Il est notamment déjà en cours de déploiement pour la VoIP résidentiel et constitue donc pour les opérateurs et constructeurs une solution universelle et largement supportée permettant de mutualiser au maximum les nouvelles infrastructures.

Le réseau IMS est basé sur l’emploi du protocole de signalisation SIP (Session Initiation Protocol) qui permet l’enregistrement du mobile au service téléphonique et l’établissement d’une session, et du protocole SDP (Session Description Protocol), associé au protocole SIP, qui supporte la négociation du média (voix, vidéo, données). La seconde fonction assurée par l’architecture IMS concerne le traitement du flux média pour les fonctions indisponibles dans le réseau 4G comme la conférence, la génération des annonces et les passerelles vers les réseaux téléphoniques fixes PSTN (Public Switched Telephone Network) et les réseaux de mobiles PLMN (Public Land Mobile Network).
L’utilisation de l’IMS constitue donc une rupture technologique dans les réseaux mobiles en étant la première à se baser entièrement sur un réseau de données IP. Cela garantit la plus grande richesse fonctionnelle, la possibilité d’introduire de véritables services de convergences voix/données ainsi que les meilleures possibilités d’évolution.
Cependant, la solution IMS nécessite un investissement conséquent car elle ne réutilise pas l’infrastructure existante. Par ailleurs, il s’agit d’un changement technologique majeur et il conviendra d’assurer dès le début une qualité de service et une expérience utilisateur au moins au niveau de celles actuelles afin d’éviter un rejet des utilisateurs. Naturellement, cette solution sera d’autant plus facile et moins risquée à déployer dès le début que l’opérateur dispose déjà d’une infrastructure IMS opérationnelle sur d’autres réseaux d’accès, ADSL par exemple. Afin de réduire ce risque lié à l’introduction immédiate d’un nouveau système complexe, les principaux acteurs de la téléphonie ont lancé l’initiative One Voice. Cette initiative a conduit à la définition d’un sous-ensemble de fonctionnalités IMS définies par le 3GPP. Ce sous-ensemble permet ainsi de simplifier le déploiement de l’IMS dans un cadre LTE tout en garantissant une interopérabilité maximale.
Conclusion
Il existe donc plusieurs solutions afin d’assurer un service de voix sur les nouveaux réseaux 4G. Par ailleurs, il n’est pas exclu que certains opérateurs choisissent une solution de type over-the-top basée une technologie non spécifique au 3GPP ou aux réseaux mobiles. Cela pourrait être un service basé sur l’utilisation simple de SIP ou bien encore sur une technologie propriétaire telle que Skype. Cependant cette approche, externe au réseau de l’opérateur, ne bénéficie alors pas des services de ce dernier (QoS, handover …). Il sera également intéressant de suivre les positions de Google et d’Apple ; en effet, Android et l’iPhone constituent les principaux terminaux susceptibles de bénéficier de LTE. Ces nouveaux acteurs ne sont pas issus de l’écosystème traditionnel des télécommunications et pourraient, une nouvelle fois, bouleverser ce marché. De plus, ils dominent le marché des tablettes en pleine croissance et à la base de nouveaux usages mobiles, ce qui pourrait influencer fortement les stratégies de déploiements LTE.
Le tableau ci-dessous présente un résumé des avantages et inconvénients de ces différentes technologies:

Il n’existe pas de solution universelle et constituant une évolution logique et sans heurts des technologies actuellement déployées. Les opérateurs devront alors trouver le meilleur compromis adapté à leur situation et à leurs objectifs. Chacun aura donc à composer avec de multiples facteurs et prendre en compte des éléments tels que:
- l’horizon de déploiement de la LTE
- la couverture LTE: hotspots uniquement ou nationale
- le type de réseau actuellement déployé et leurs potentielles évolutions
- l’introduction de nouveaux services notamment de convergence
- la volonté ou non de franchir le pas tout IP au plus vite
- les technologies supportées par les partenaires de roaming ainsi que les fournisseurs de terminaux
A l’heure actuelle, il semble qu’un consensus se dégage en faveur d’une solution IMS mais, pour séduisante qu’elle soit sur le papier et à long terme, il s’agit également de la solution qui nécessite les changements les plus radicaux. CSFB est une technologie de transition simple à mettre en oeuvre mais il reste à voir si ses défauts pourront être acceptés par les utilisateurs. VoLGA est apparu comme une meilleure solution d’intérim mais souffre toujours d’un déficit d’adoption au niveau de la standardisation, ce qui compromet fortement son avenir. Enfin, SVLTE semble susciter de l’intérêt et, si les impacts sur le terminal se révèlent acceptables, pourrait constituer la solution transitoire la plus simple à mettre en oeuvre avant de basculer sur IMS.
Il sera donc intéressant d’observer dès 2012 les premiers déploiements LTE et les solutions retenues, ce qui fera l’objet de prochains articles. Nous aborderons également les technologies permettant de gérer le handover 2G/3G et LTE. En effet, la couverture LTE ne devrait être que partielle au début et il faudra également assurer la continuité du service voix en cas de sortie de cette couverture.
6 janvier 2012
L’un des problèmes les plus fréquemment rencontrés lors du déploiement d’un système VoIP est celui de la traversée de NAT. Bien que le principe du NAT en lui-même soit relativement simple, les conséquences sur les protocoles de VoIP sont assez complexes et il n’existe malheureusement pas de solutions simples et universelles pour y remédier. Dans cette série d’articles, nous décrirons les difficultés rencontrées lors d’un déploiement VoIP en présence de NAT ainsi que les différentes solutions, que ce soit dans les équipements disponibles du commerce ou dans les spécifications récentes et non encore mises en pratique. Dans ce premier article, nous allons examiner ce qu’est le NAT, les raisons de l’introduction de ce mécanisme et son principe général de fonctionnement.
Les origines du mécanisme de NAT (Network Address Translation) sont intimement liées avec la démocratisation des accès à Internet au cours des années 1990. Ce réseau global se repose en effet sur l’utilisation de IPv4 (Internet Protocol version 4) qui, lorsqu’il a été défini au début des années 80, n’avait jamais envisagé une telle expansion. Il faut en effet comprendre que tout équipement souhaitant communiquer au sein d’un réseau (et par conséquent, Internet aussi), doit impérativement disposer d’une adresse IP unique, tout comme une habitation afin de pouvoir recevoir du courrier par exemple. Alors que cette dernière se repose sur le nom de rue, ville, code postal …, IPv4 code ses adresses sur 32 bits, ce qui permet de disposer d’un peu plus de 4 milliards d’adresses différentes. Au début d’Internet, ce nombre paraissant plus que suffisant et l’on ne pensait pas manquer d’adresses disponibles.

Cependant avec l’explosion des demandes d’accès, que ce soit par des particuliers ou des entreprises (pouvant utiliser parfois quelques dizaines, centaines, voire plus, d’adresses) ainsi qu’une méthode d’attribution ayant conduit à des gaspillages importants, il est apparu, dès le début des années 90, qu’un épuisement était inévitable à moyen terme.
(suite…)